Publications
2025
- COLING2025
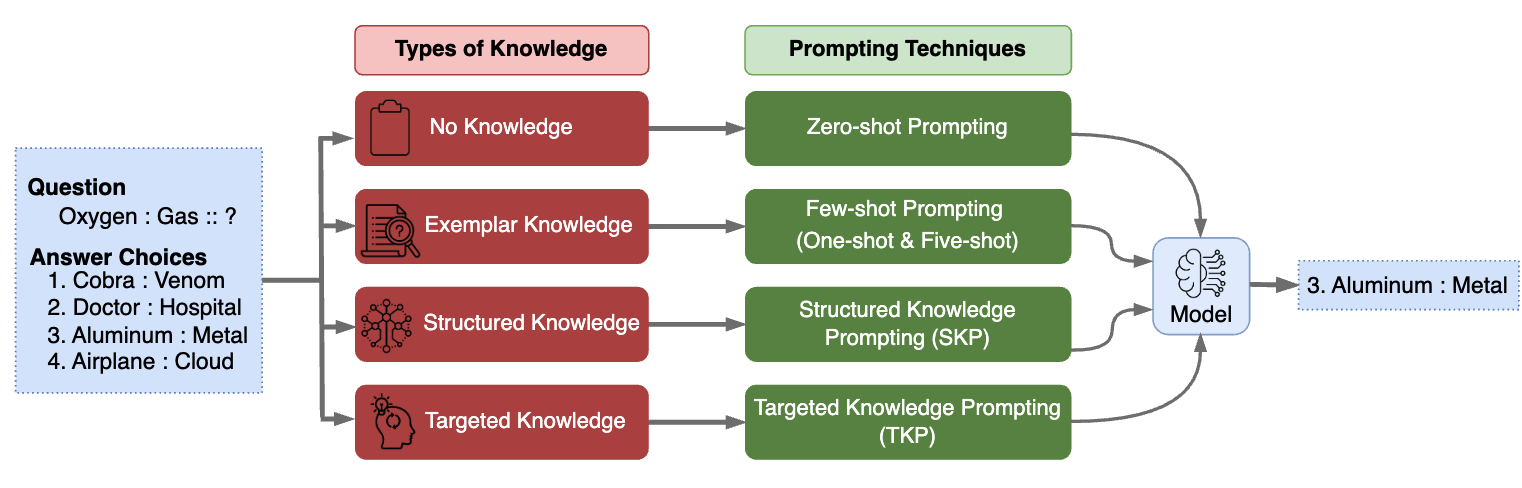 Exploring the Abilities of Large Language Models to Solve Proportional Analogies via Knowledge-Enhanced PromptingThilini Wijesiriwardene, Ruwan Wickramarachchi, Sreeram Vennam, and 5 more authorsIn The 31st International Conference on Computational Linguistics (COLING 2025), 2025
Exploring the Abilities of Large Language Models to Solve Proportional Analogies via Knowledge-Enhanced PromptingThilini Wijesiriwardene, Ruwan Wickramarachchi, Sreeram Vennam, and 5 more authorsIn The 31st International Conference on Computational Linguistics (COLING 2025), 2025Making analogies is fundamental to cognition. Proportional analogies, which consist of four terms, are often used to assess linguistic and cognitive abilities. For instance, completing analogies like “Oxygen is to Gas as \<blank\>is to \<blank\>” requires identifying the semantic relationship (e.g., “type of”) between the first pair of terms (“Oxygen” and “Gas”) and finding a second pair that shares the same relationship (e.g., “Aluminum” and “Metal”). In this work, we introduce a 15K Multiple-Choice Question Answering (MCQA) dataset for proportional analogy completion and evaluate the performance of contemporary Large Language Models (LLMs) in various knowledge-enhanced prompt settings. Specifically, we augment prompts with three types of knowledge: exemplar, structured, and targeted. Our results show that despite extensive training data, solving proportional analogies remains challenging for current LLMs, with the best model achieving an accuracy of 55%. Notably, we find that providing targeted knowledge can better assist models in completing proportional analogies compared to providing exemplars or collections of structured knowledge.
@inproceedings{wijesiriwardene2024exploring, title = {Exploring the Abilities of Large Language Models to Solve Proportional Analogies via Knowledge-Enhanced Prompting}, author = {Wijesiriwardene, Thilini and Wickramarachchi, Ruwan and Vennam, Sreeram and Jain, Vinija and Chadha, Aman and Das, Amitava and Kumaraguru, Ponnurangam and Sheth, Amit}, booktitle = {The 31st International Conference on Computational Linguistics (COLING 2025)}, year = {2025}, }
2024
- IEEE-IC
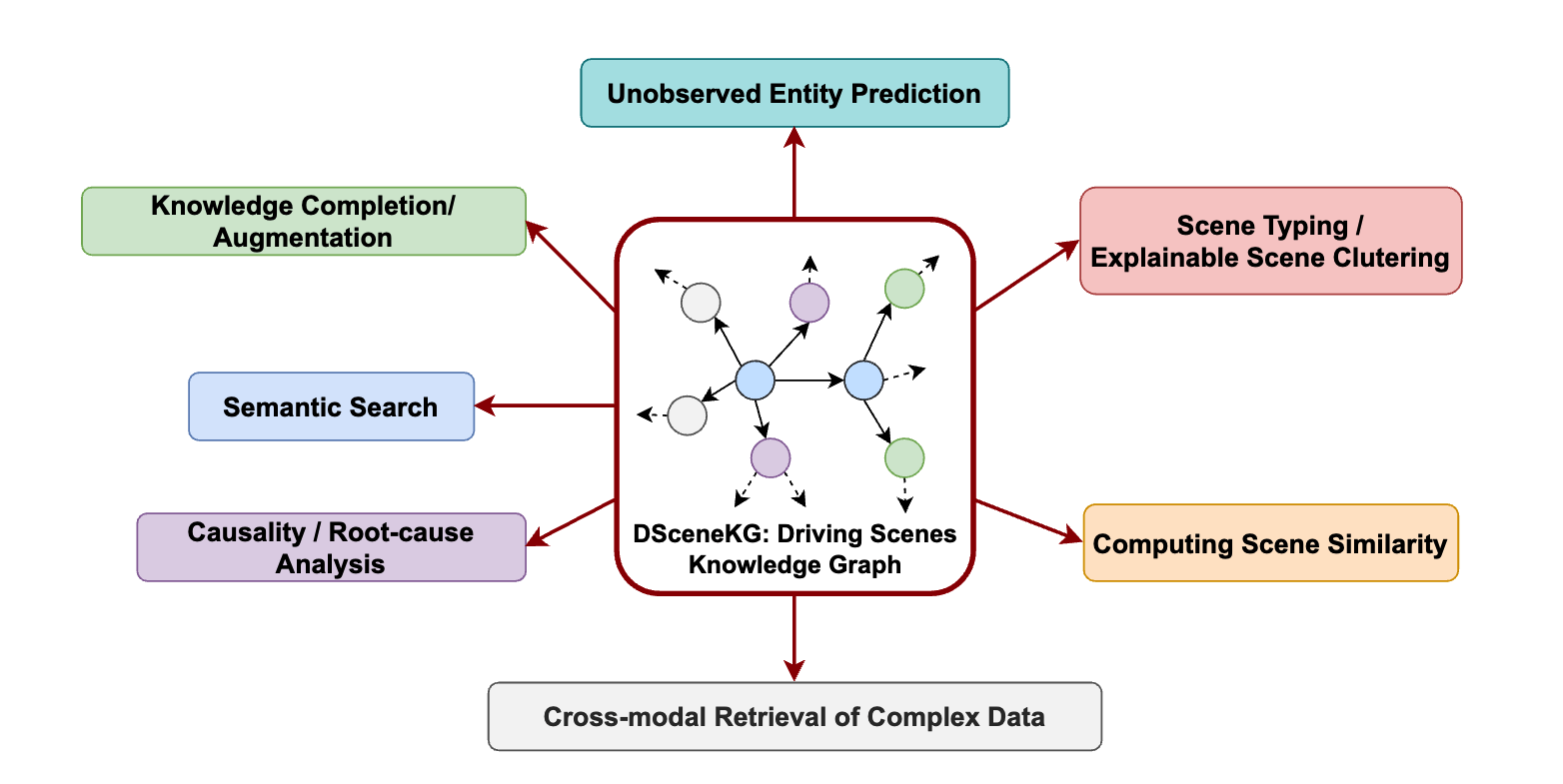 Knowledge Graphs of Driving Scenes to Empower the Emerging Capabilities of Neurosymbolic AIRuwan Wickramarachchi, Cory Henson, and Amit ShethIn IEEE Internet Computing, 2024
Knowledge Graphs of Driving Scenes to Empower the Emerging Capabilities of Neurosymbolic AIRuwan Wickramarachchi, Cory Henson, and Amit ShethIn IEEE Internet Computing, 2024In the era of Generative AI, Neurosymbolic AI is emerging as a powerful approach for tasks spanning from perception to cognition. The use of Neurosymbolic AI has been shown to achieve enhanced capabilities, including improved grounding, alignment, explainability, and reliability. However, due to its nascent stage, there is a lack of widely available real-world benchmark datasets tailored to Neurosymbolic AI tasks. To address this gap and support the evaluation of current and future methods, we introduce DSceneKG – a suite of knowledge graphs of driving scenes built from real-world, high-quality scenes from multiple open autonomous driving datasets. In this article, we detail the construction process of DSceneKG and highlight its application in seven different tasks.
@inproceedings{wickramarachchi2024knowledge, title = {Knowledge Graphs of Driving Scenes to Empower the Emerging Capabilities of Neurosymbolic AI}, author = {Wickramarachchi, Ruwan and Henson, Cory and Sheth, Amit}, booktitle = {IEEE Internet Computing}, year = {2024}, } - ISWC2024
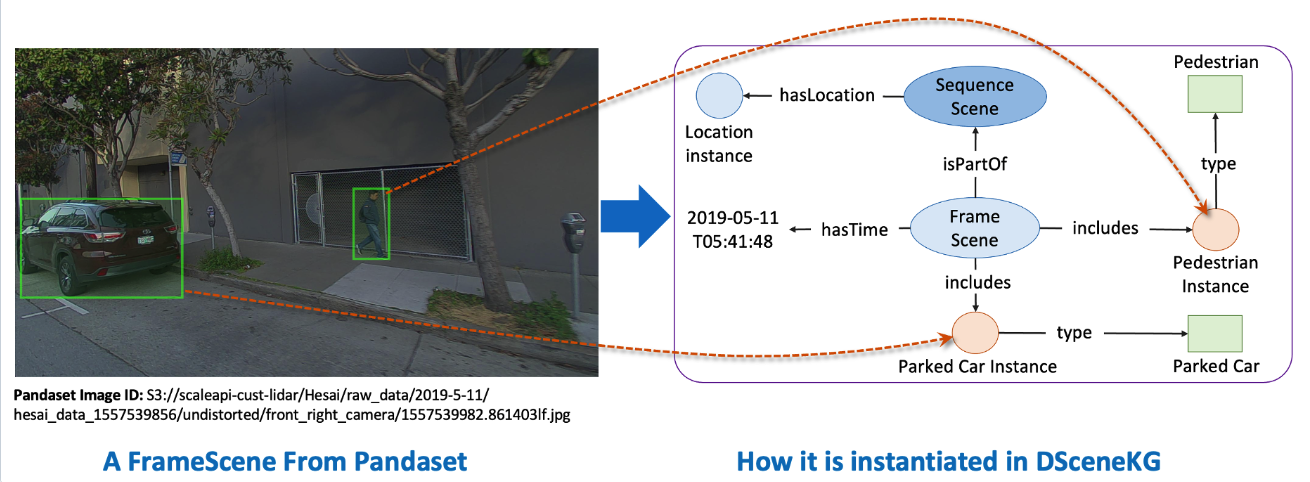 A Benchmark Knowledge Graph of Driving Scenes for Knowledge Completion TasksRuwan Wickramarachchi, Cory Henson, and Amit ShethIn The 23rd International Semantic Web Conference (ISWC), 2024
A Benchmark Knowledge Graph of Driving Scenes for Knowledge Completion TasksRuwan Wickramarachchi, Cory Henson, and Amit ShethIn The 23rd International Semantic Web Conference (ISWC), 2024Knowledge graph completion (KGC) is a problem of significant importance due to the inherent incompleteness in knowledge graphs (KGs). The current approaches for KGC using link prediction (LP) mostly rely on a common set of benchmark datasets that are quite different from real-world industrial KGs. Therefore, the adaptability of current LP methods for real-world KGs and domain-specific applications is questionable. To support the evaluation of current and future LP and KGC methods for industrial KGs, we introduce DSceneKG, a suite of real-world driving scene knowledge graphs that are currently being used across various industrial applications. The DSceneKG is publicly available at: https://github.com/ruwantw/DSceneKG.
@inproceedings{wickramarachchi2024benchmark, title = {A Benchmark Knowledge Graph of Driving Scenes for Knowledge Completion Tasks}, author = {Wickramarachchi, Ruwan and Henson, Cory and Sheth, Amit}, booktitle = {The 23rd International Semantic Web Conference (ISWC)}, year = {2024}, } - EACL2024
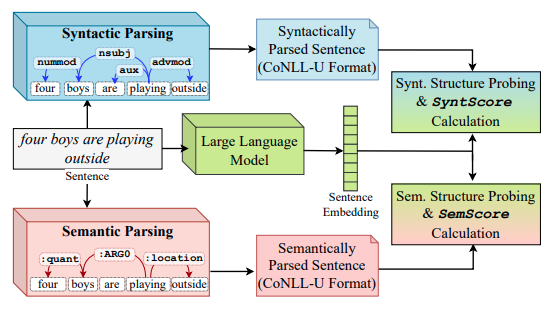 On the Relationship between Sentence Analogy Identification and Sentence Structure Encoding in Large Language ModelsThilini Wijesiriwardene, Ruwan Wickramarachchi, Aishwarya Naresh Reganti, and 4 more authorsIn Findings of the Association for Computational Linguistics: EACL 2024, 2024
On the Relationship between Sentence Analogy Identification and Sentence Structure Encoding in Large Language ModelsThilini Wijesiriwardene, Ruwan Wickramarachchi, Aishwarya Naresh Reganti, and 4 more authorsIn Findings of the Association for Computational Linguistics: EACL 2024, 2024The ability of Large Language Models (LLMs) to encode syntactic and semantic structures of language is well examined in NLP. Additionally, analogy identification, in the form of word analogies are extensively studied in the last decade of language modeling literature. In this work we specifically look at how LLMs’ abilities to capture sentence analogies (sentences that convey analogous meaning to each other) vary with LLMs’ abilities to encode syntactic and semantic structures of sentences. Through our analysis, we find that LLMs’ ability to identify sentence analogies is positively correlated with their ability to encode syntactic and semantic structures of sentences. Specifically, we find that the LLMs which capture syntactic structures better, also have higher abilities in identifying sentence analogies.
@inproceedings{wijesiriwardene2024relationship, title = {On the Relationship between Sentence Analogy Identification and Sentence Structure Encoding in Large Language Models}, author = {Wijesiriwardene, Thilini and Wickramarachchi, Ruwan and Reganti, Aishwarya Naresh and Jain, Vinija and Chadha, Aman and Sheth, Amit and Das, Amitava}, booktitle = {Findings of the Association for Computational Linguistics: EACL 2024}, pages = {451--457}, year = {2024}, } - ACM-CSUR
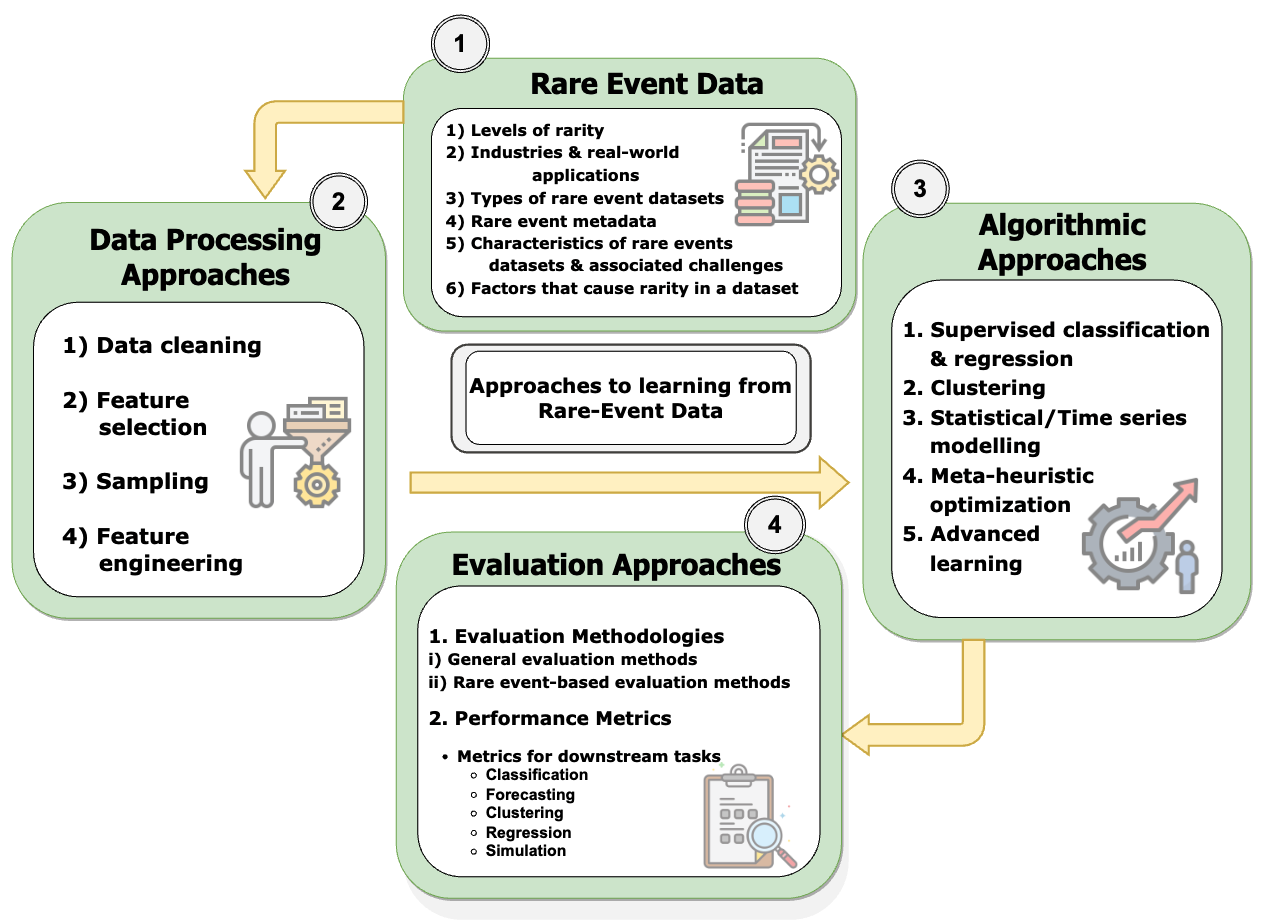 A Comprehensive Survey on Rare Event PredictionChathurangi Shyalika, Ruwan Wickramarachchi, and Amit P. ShethACM Comput. Surv., Oct 2024
A Comprehensive Survey on Rare Event PredictionChathurangi Shyalika, Ruwan Wickramarachchi, and Amit P. ShethACM Comput. Surv., Oct 2024Rare event prediction involves identifying and forecasting events with a low probability using machine learning (ML) and data analysis. Due to the imbalanced data distributions, where the frequency of common events vastly outweighs that of rare events, it requires using specialized methods within each step of the ML pipeline, i.e., from data processing to algorithms to evaluation protocols. Predicting the occurrences of rare events is important for real-world applications, such as Industry 4.0, and is an active research area in statistical and ML. This paper comprehensively reviews the current approaches for rare event prediction along four dimensions: rare event data, data processing, algorithmic approaches, and evaluation approaches. Specifically, we consider 73 datasets from different modalities (i.e., numerical, image, text, and audio), four major categories of data processing, five major algorithmic groupings, and two broader evaluation approaches. This paper aims to identify gaps in the current literature and highlight the challenges of predicting rare events. It also suggests potential research directions, which can help guide practitioners and researchers.
@article{shyalika2024comprehensive, author = {Shyalika, Chathurangi and Wickramarachchi, Ruwan and Sheth, Amit P.}, title = {A Comprehensive Survey on Rare Event Prediction}, year = {2024}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, issn = {0360-0300}, url = {https://doi.org/10.1145/3699955}, doi = {10.1145/3699955}, journal = {ACM Comput. Surv.}, month = oct, keywords = {event-prediction, rare-events, time-series, anomaly prediction, forecasting} } - KDD-KiL
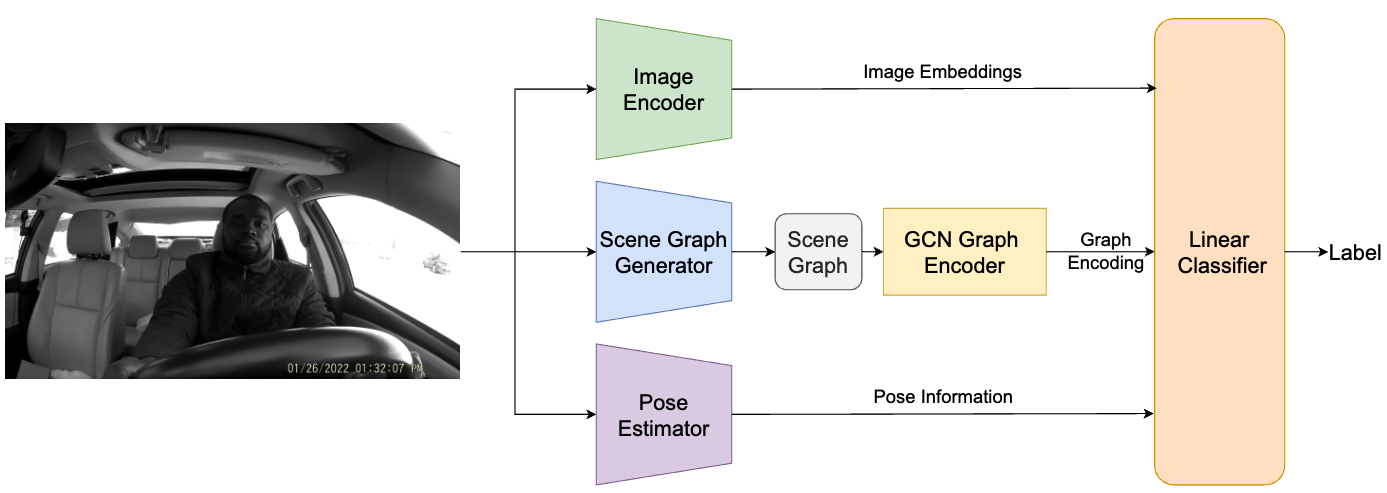 Towards Infusing Auxiliary Knowledge for Distracted Driver DetectionIshwar B Balappanawar, Ashmit Chamoli, Ruwan Wickramarachchi, and 2 more authorsIn Fourth Workshop on Knowledge-infused Learning co-located with 30th ACM KDD Conference, Barcelona, Spain, Oct 2024
Towards Infusing Auxiliary Knowledge for Distracted Driver DetectionIshwar B Balappanawar, Ashmit Chamoli, Ruwan Wickramarachchi, and 2 more authorsIn Fourth Workshop on Knowledge-infused Learning co-located with 30th ACM KDD Conference, Barcelona, Spain, Oct 2024Distracted driving is a leading cause of road accidents globally. Identification of distracted driving involves reliably detecting and classifying various forms of driver distraction (e.g., texting, eating, or using in-car devices) from in-vehicle camera feeds to enhance road safety. This task is challenging due to the need for robust models that can generalize to a diverse set of driver behaviors without requiring extensive annotated datasets. In this paper, we propose KiD3, a novel method for distracted driver detection (DDD) by infusing auxiliary knowledge about semantic relations between entities in a scene and the structural configuration of the driver’s pose. Specifically, we construct a unified framework that integrates the scene graphs, and driver’s pose information with the visual cues in video frames to create a holistic representation of the driver’s actions. Our results indicate that KiD3 achieves a 13.64% accuracy improvement over the vision-only baseline by incorporating such auxiliary knowledge with visual information.
@inproceedings{balappanawar2024towards, title = {Towards Infusing Auxiliary Knowledge for Distracted Driver Detection}, author = {Balappanawar, Ishwar B and Chamoli, Ashmit and Wickramarachchi, Ruwan and Mishra, Aditya and Kumaraguru, Ponnurangam}, booktitle = {Fourth Workshop on Knowledge-infused Learning co-located with 30th ACM KDD Conference, Barcelona, Spain}, year = {2024}, } - Sensors
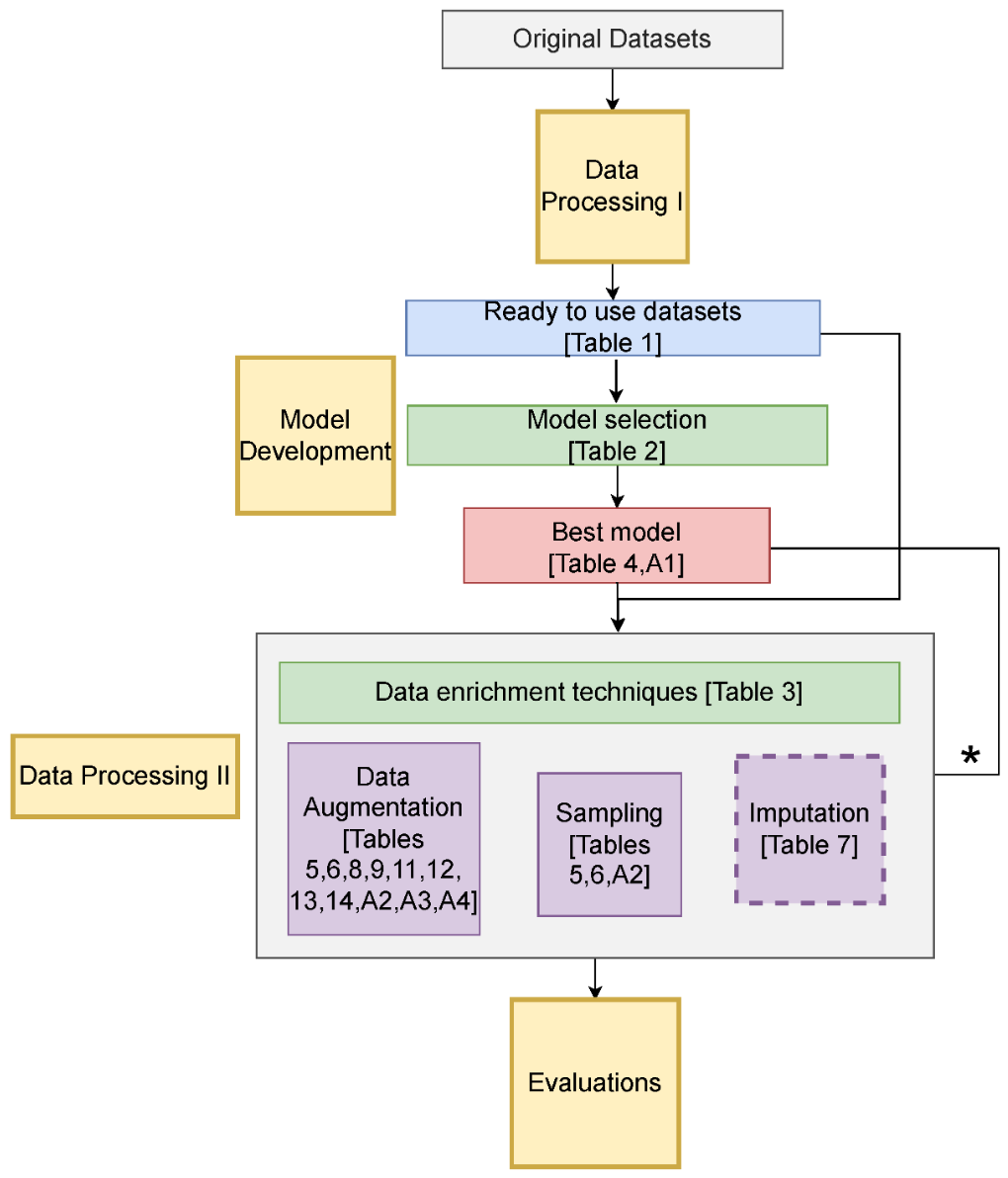 Evaluating the Role of Data Enrichment Approaches towards Rare Event Analysis in ManufacturingChathurangi Shyalika, Ruwan Wickramarachchi, Fadi El Kalach, and 2 more authorsSensors, Oct 2024
Evaluating the Role of Data Enrichment Approaches towards Rare Event Analysis in ManufacturingChathurangi Shyalika, Ruwan Wickramarachchi, Fadi El Kalach, and 2 more authorsSensors, Oct 2024Rare events are occurrences that take place with a significantly lower frequency than more common, regular events. These events can be categorized into distinct categories, from frequently rare to extremely rare, based on factors like the distribution of data and significant differences in rarity levels. In manufacturing domains, predicting such events is particularly important, as they lead to unplanned downtime, a shortening of equipment lifespans, and high energy consumption. Usually, the rarity of events is inversely correlated with the maturity of a manufacturing industry. Typically, the rarity of events affects the multivariate data generated within a manufacturing process to be highly imbalanced, which leads to bias in predictive models. This paper evaluates the role of data enrichment techniques combined with supervised machine learning techniques for rare event detection and prediction. We use time series data augmentation and sampling to address the data scarcity, maintaining its patterns, and imputation techniques to handle null values. Evaluating 15 learning models, we find that data enrichment improves the F1 measure by up to 48% in rare event detection and prediction. Our empirical and ablation experiments provide novel insights, and we also investigate model interpretability.
@article{shyalika2024evaluating, title = {Evaluating the Role of Data Enrichment Approaches towards Rare Event Analysis in Manufacturing}, author = {Shyalika, Chathurangi and Wickramarachchi, Ruwan and El Kalach, Fadi and Harik, Ramy and Sheth, Amit}, journal = {Sensors}, volume = {24}, number = {15}, pages = {5009}, year = {2024}, publisher = {MDPI}, } - ISWC-WOP
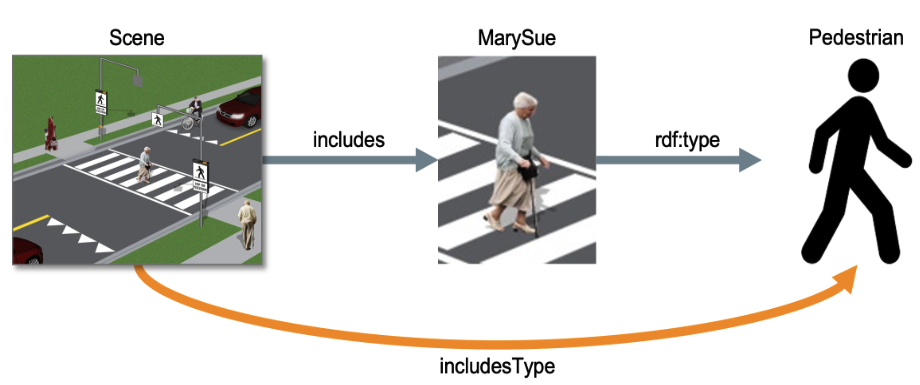 Ontology Design Metapattern for RelationType Role CompositionUtkarshani Jaimini, Ruwan Wickramarachchi, Cory Henson, and 1 more authorIn International Semantic Web Conference, Oct 2024
Ontology Design Metapattern for RelationType Role CompositionUtkarshani Jaimini, Ruwan Wickramarachchi, Cory Henson, and 1 more authorIn International Semantic Web Conference, Oct 2024RelationType is a metapattern that specifies a property in a knowledge graph that directly links the head of a triple with the type of the tail. This metapattern is useful for knowledge graph link prediction tasks, specifically when one wants to predict the type of a linked entity rather than the entity instance itself. The RelationType metapattern serves as a template for future extensions of an ontology with more fine-grained domain information.
@inproceedings{jaimini2024ontology, title = {Ontology Design Metapattern for RelationType Role Composition}, author = {Jaimini, Utkarshani and Wickramarachchi, Ruwan and Henson, Cory and Sheth, Amit}, booktitle = {International Semantic Web Conference}, year = {2024}, }
2023
- ACL2023
 ANALOGICAL-A Novel Benchmark for Long Text Analogy Evaluation in Large Language ModelsThilini Wijesiriwardene, Ruwan Wickramarachchi, Bimal Gajera, and 6 more authorsIn Findings of the Association for Computational Linguistics: ACL 2023, Oct 2023
ANALOGICAL-A Novel Benchmark for Long Text Analogy Evaluation in Large Language ModelsThilini Wijesiriwardene, Ruwan Wickramarachchi, Bimal Gajera, and 6 more authorsIn Findings of the Association for Computational Linguistics: ACL 2023, Oct 2023Over the past decade, analogies, in the form of word-level analogies, have played a significant role as an intrinsic measure of evaluating the quality of word embedding methods such as word2vec. Modern large language models (LLMs), however, are primarily evaluated on extrinsic measures based on benchmarks such as GLUE and SuperGLUE, and there are only a few investigations on whether LLMs can draw analogies between long texts. In this paper, we present ANALOGICAL, a new benchmark to intrinsically evaluate LLMs across a taxonomy of analogies of long text with six levels of complexity – (i) word, (ii) word vs. sentence, (iii) syntactic, (iv) negation, (v) entailment, and (vi) metaphor. Using thirteen datasets and three different distance measures, we evaluate the abilities of eight LLMs in identifying analogical pairs in the semantic vector space. Our evaluation finds that it is increasingly challenging for LLMs to identify analogies when going up the analogy taxonomy.
@inproceedings{wijesiriwardene2023analogical, title = {ANALOGICAL-A Novel Benchmark for Long Text Analogy Evaluation in Large Language Models}, author = {Wijesiriwardene, Thilini and Wickramarachchi, Ruwan and Gajera, Bimal and Gowaikar, Shreeyash and Gupta, Chandan and Chadha, Aman and Reganti, Aishwarya Naresh and Sheth, Amit and Das, Amitava}, booktitle = {Findings of the Association for Computational Linguistics: ACL 2023}, pages = {3534--3549}, year = {2023}, } - AAAI2023
 CLUE-AD: A context-based method for labeling unobserved entities in autonomous driving dataRuwan Wickramarachchi, Cory Henson, and Amit ShethIn Proceedings of the AAAI Conference on Artificial Intelligence, Oct 2023
CLUE-AD: A context-based method for labeling unobserved entities in autonomous driving dataRuwan Wickramarachchi, Cory Henson, and Amit ShethIn Proceedings of the AAAI Conference on Artificial Intelligence, Oct 2023Generating high-quality annotations for object detection and recognition is a challenging and important task, especially in relation to safety-critical applications such as autonomous driving (AD). Due to the difficulty of perception in challenging situations such as occlusion, degraded weather, and sensor failure, objects can go unobserved and unlabeled. In this paper, we present CLUE-AD, a general-purpose method for detecting and labeling unobserved entities by leveraging the object continuity assumption within the context of a scene. This method is dataset-agnostic, supporting any existing and future AD datasets. Using a real-world dataset representing complex urban driving scenes, we demonstrate the applicability of CLUE-AD for detecting unobserved entities and augmenting the scene data with new labels.
@inproceedings{wickramarachchi2023clue, title = {CLUE-AD: A context-based method for labeling unobserved entities in autonomous driving data}, author = {Wickramarachchi, Ruwan and Henson, Cory and Sheth, Amit}, booktitle = {Proceedings of the AAAI Conference on Artificial Intelligence}, volume = {37}, number = {13}, pages = {16491--16493}, year = {2023}, } - IEEE-IS
 A semantic web approach to fault tolerant autonomous manufacturingFadi El Kalach, Ruwan Wickramarachchi, Ramy Harik, and 1 more authorIEEE Intelligent Systems, Oct 2023
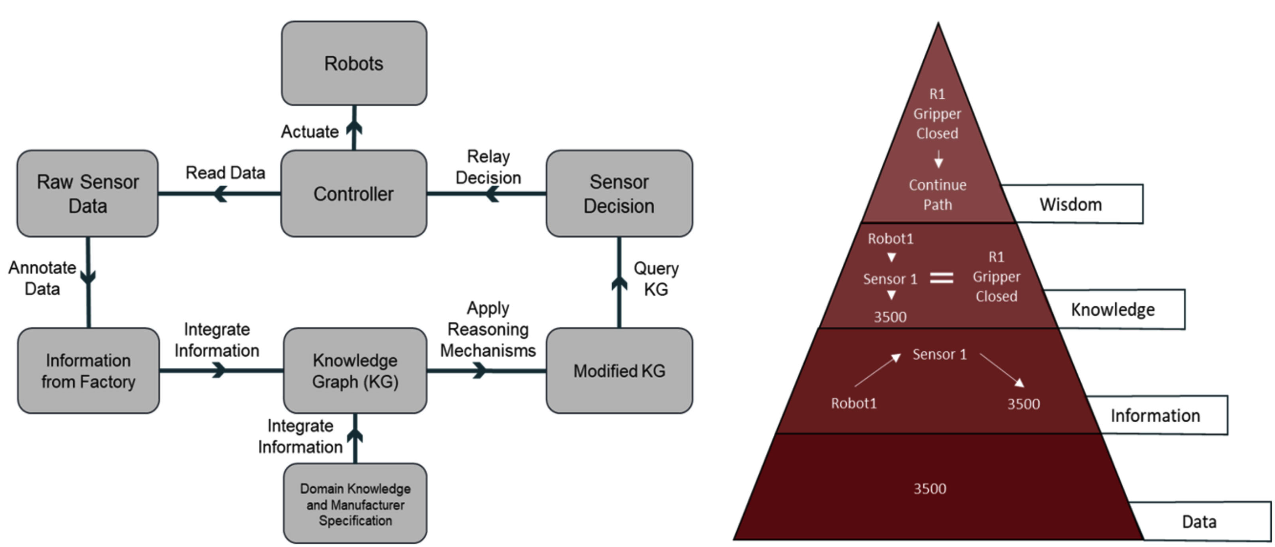
A semantic web approach to fault tolerant autonomous manufacturingFadi El Kalach, Ruwan Wickramarachchi, Ramy Harik, and 1 more authorIEEE Intelligent Systems, Oct 2023The next phase of manufacturing is centered on making the switch from traditional automated to autonomous systems. Future factories are required to be agile, allowing for more customized production and resistance to disturbances. Such production lines would be able to reallocate resources as needed and minimize downtime while keeping up with market demands. These systems must be capable of complex decision-making based on parameters, such as machine status, sensory/IoT data, and inspection results. Current manufacturing lines lack this complex capability and instead focus on low-level decision-making on the machine level without utilizing the generated data to its full extent. This article presents progress toward this autonomy by introducing Semantic Web capabilities applied to managing the production line. Finally, a full autonomous manufacturing use case is also developed to showcase the value of Semantic Web in a manufacturing context. This use case utilizes diverse data sources and domain knowledge to complete a manufacturing process despite malfunctioning equipment. It highlights the benefit of Semantic Web in manufacturing by integrating the heterogeneous information required for the process to be completed. This provides an approach to autonomous manufacturing not yet fully realized at the intersection of Semantic Web and manufacturing.
@article{el2023semantic, title = {A semantic web approach to fault tolerant autonomous manufacturing}, author = {El Kalach, Fadi and Wickramarachchi, Ruwan and Harik, Ramy and Sheth, Amit}, journal = {IEEE Intelligent Systems}, volume = {38}, number = {1}, pages = {69--75}, year = {2023}, publisher = {IEEE}, }
{kind=link}
2022
- Analogies22@ICCBR
 Towards efficient scoring of student-generated long-form analogies in STEMThilini Wijesiriwardene, Ruwan Wickramarachchi, Valerie L Shalin, and 1 more authorIn The International Conference on Case-Based Reasoning (ICCBR) Analogies’22: Workshop on Analogies: from Theory to Applications at ICCBR-2022, September, 2022, Nancy, France, Oct 2022
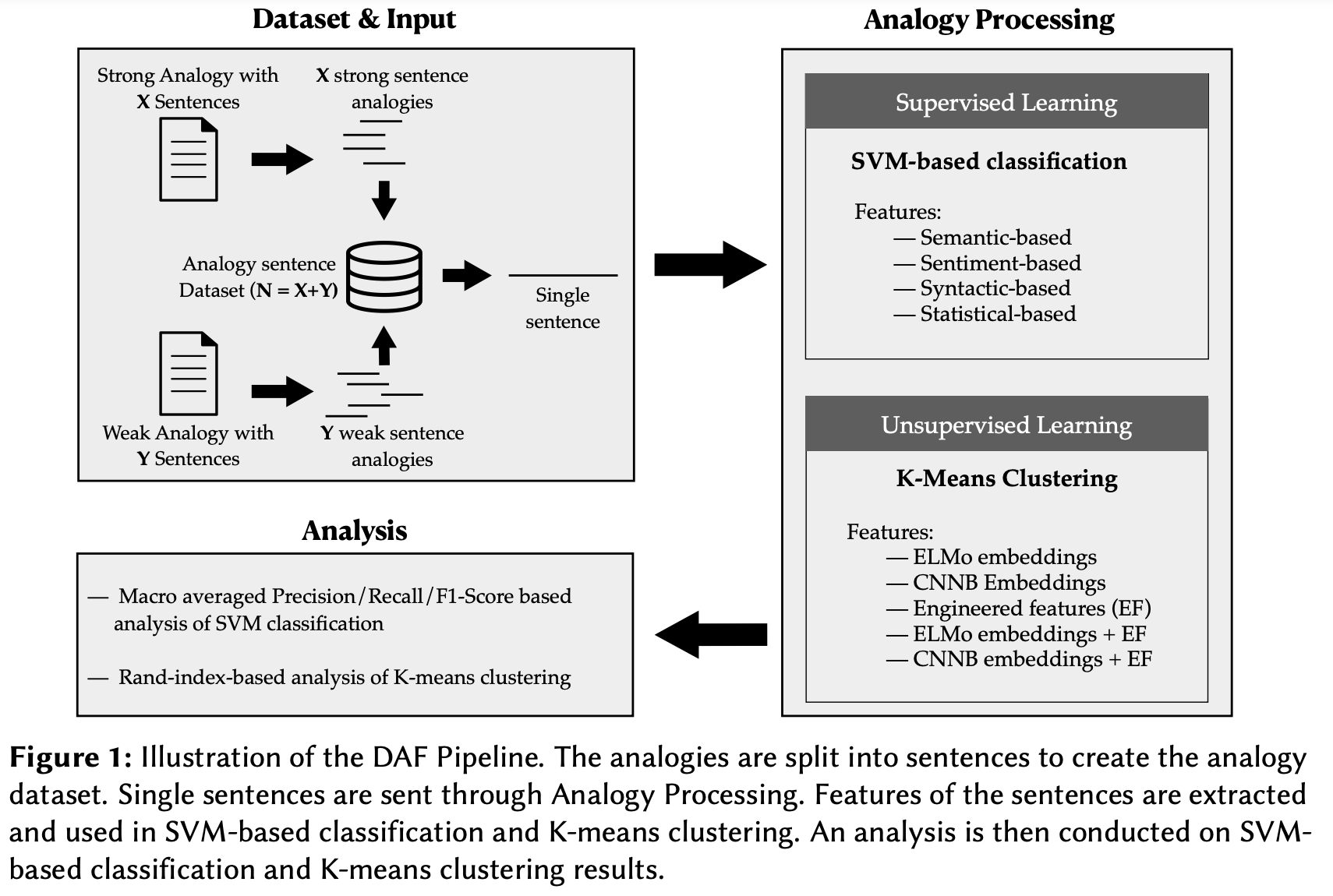
Towards efficient scoring of student-generated long-form analogies in STEMThilini Wijesiriwardene, Ruwan Wickramarachchi, Valerie L Shalin, and 1 more authorIn The International Conference on Case-Based Reasoning (ICCBR) Analogies’22: Workshop on Analogies: from Theory to Applications at ICCBR-2022, September, 2022, Nancy, France, Oct 2022Switching from an analogy pedagogy based on comprehension to analogy pedagogy based on production raises an impractical manual analogy scoring problem. Conventional symbol-matching approaches to computational analogy evaluation focus on positive cases, and challenge computational feasibility. This work presents the Discriminative Analogy Features (DAF) pipeline to identify the discriminative features of strong and weak long-form text analogies. We introduce four feature categories (semantic, syntactic, sentiment, and statistical) used with supervised vector-based learning methods to discriminate between strong and weak analogies. Using a modestly sized vector of engineered features with SVM attains a 0.67 macro F1 score. While a semantic feature is the most discriminative, out of the top 15 discriminative features, most are syntactic. Combining these engineered features with an ELMo-generated embedding still improves classification relative to an embedding alone. While an unsupervised K-Means clustering-based approach falls short, similar hints of improvement appear when inputs include the engineered features used in supervised learning.
@inproceedings{wijesiriwardene2022towards, title = {Towards efficient scoring of student-generated long-form analogies in STEM}, author = {Wijesiriwardene, Thilini and Wickramarachchi, Ruwan and Shalin, Valerie L and Sheth, Amit P}, booktitle = {The International Conference on Case-Based Reasoning (ICCBR) Analogies’22: Workshop on Analogies: from Theory to Applications at ICCBR-2022, September, 2022, Nancy, France}, year = {2022} } - ISWC2022
 Tutorial: Knowledge-infused Learning for Autonomous Driving (KL4AD)Ruwan Wickramarachchi, Cory Henson, Sebastian Monka, and 2 more authorsIn The 21st International Semantic Web Conference (ISWC), Oct 2022
Tutorial: Knowledge-infused Learning for Autonomous Driving (KL4AD)Ruwan Wickramarachchi, Cory Henson, Sebastian Monka, and 2 more authorsIn The 21st International Semantic Web Conference (ISWC), Oct 2022Autonomous Driving (AD) is considered as a testbed for tackling many hard AI problems. Despite the recent advancements in the field, AD is still far from achieving full autonomy due to core technical problems inherent in AD. The emerging field of neuro-symbolic AI and the methods for knowledge-infused learning are showing exciting ways of leveraging external knowledge within machine/deep learning solutions, with the potential benefits for interpretability, explainability, robustness, and transferability. In this tutorial, we will examine the use of knowledge-infused learning for three core state-of-the-art technical achievements within the AD domain. With a collaborative team from both academia and industry, we will demonstrate recent innovations using real-world datasets.
@inproceedings{wickramarachchi2022tutorial, title = {Tutorial: Knowledge-infused Learning for Autonomous Driving (KL4AD)}, author = {Wickramarachchi, Ruwan and Henson, Cory and Monka, Sebastian and Stepanova, Daria and Sheth, Amit}, booktitle = {The 21st International Semantic Web Conference (ISWC)}, year = {2022}, } - IEEE-IS
 Knowledge-based Entity Prediction for Improved Machine Perception in Autonomous SystemsRuwan Wickramarachchi, Cory Henson, and Amit ShethIEEE Intelligent Systems, Oct 2022
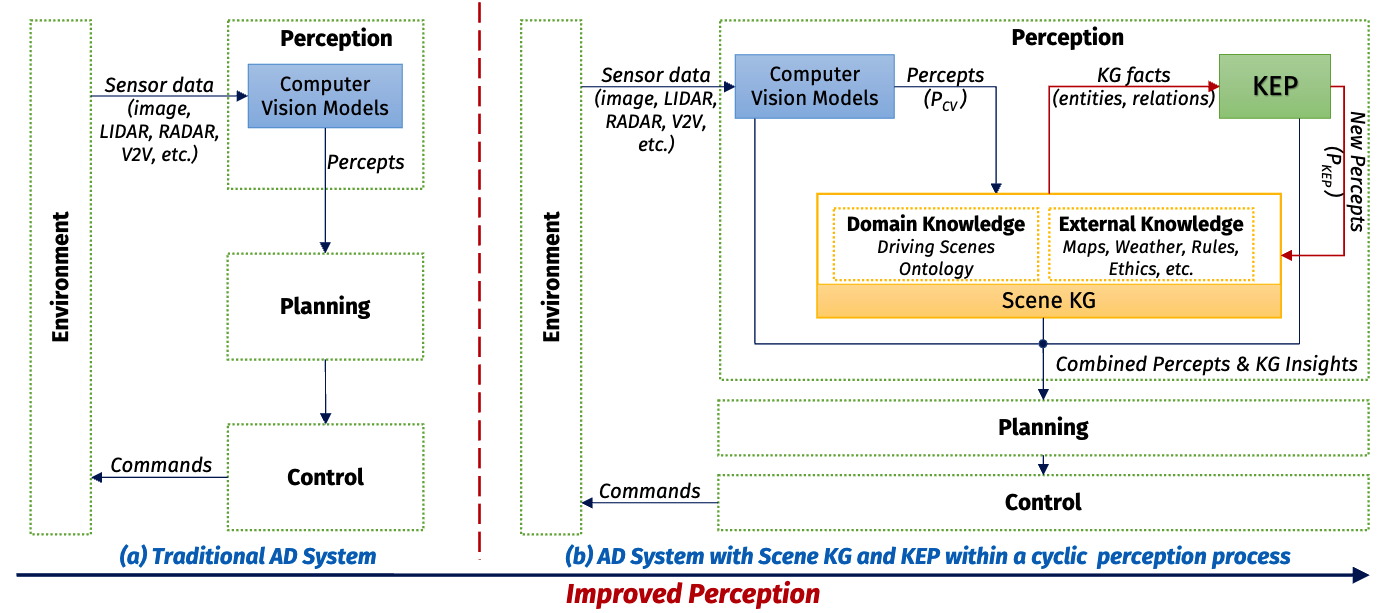
Knowledge-based Entity Prediction for Improved Machine Perception in Autonomous SystemsRuwan Wickramarachchi, Cory Henson, and Amit ShethIEEE Intelligent Systems, Oct 2022Knowledge-based entity prediction (KEP) is a novel task that aims to improve machine perception in autonomous systems. KEP leverages relational knowledge from heterogeneous sources in predicting potentially unrecognized entities. In this article, we provide a formal definition of KEP as a knowledge completion task. Three potential solutions are then introduced, which employ several machine learning and data mining techniques. Finally, the applicability of KEP is demonstrated on two autonomous systems from different domains; namely, autonomous driving and smart manufacturing. We argue that in complex real-world systems, the use of KEP would significantly improve machine perception while pushing the current technology one step closer to achieving full autonomy.
@article{wickramarachchi2022knowledge, title = {Knowledge-based Entity Prediction for Improved Machine Perception in Autonomous Systems}, author = {Wickramarachchi, Ruwan and Henson, Cory and Sheth, Amit}, journal = {IEEE Intelligent Systems}, volume = {37}, number = {5}, pages = {42--49}, year = {2022}, publisher = {IEEE}, }
2021
- Frontiers
 Knowledge-infused Learning for Entity Prediction in Driving ScenesRuwan Wickramarachchi, Cory Henson, and Amit ShethFrontiers in Big Data, Oct 2021
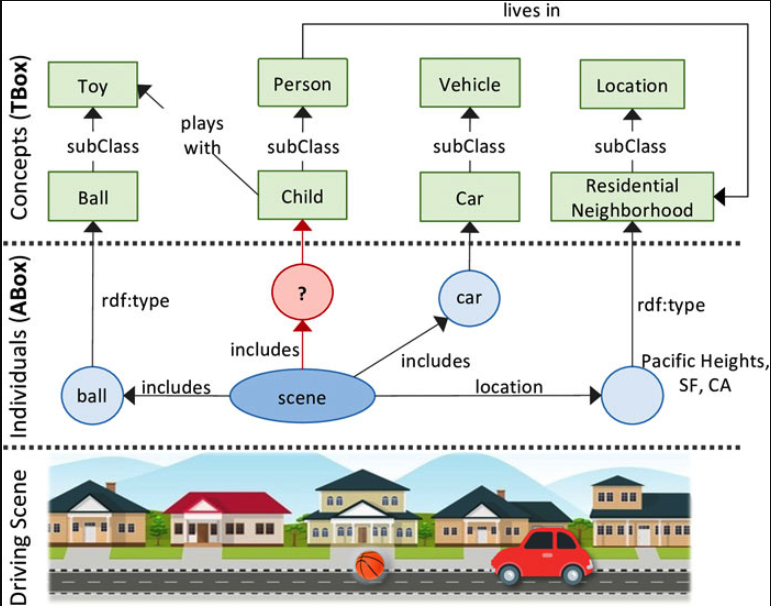
Knowledge-infused Learning for Entity Prediction in Driving ScenesRuwan Wickramarachchi, Cory Henson, and Amit ShethFrontiers in Big Data, Oct 2021Scene understanding is a key technical challenge within the autonomous driving domain. It requires a deep semantic understanding of the entities and relations found within complex physical and social environments that is both accurate and complete. In practice, this can be accomplished by representing entities in a scene and their relations as a knowledge graph (KG). This scene knowledge graph may then be utilized for the task of entity prediction, leading to improved scene understanding. In this paper, we will define and formalize this problem as Knowledge-based Entity Prediction (KEP). KEP aims to improve scene understanding by predicting potentially unrecognized entities by leveraging heterogeneous, high-level semantic knowledge of driving scenes. An innovative neuro-symbolic solution for KEP is presented, based on knowledge-infused learning, which 1) introduces a dataset agnostic ontology to describe driving scenes, 2) uses an expressive, holistic representation of scenes with knowledge graphs, and 3) proposes an effective, non-standard mapping of the KEP problem to the problem of link prediction (LP) using knowledge-graph embeddings (KGE). Using real, complex and high-quality data from urban driving scenes, we demonstrate its effectiveness by showing that the missing entities may be predicted with high precision (0.87 Hits@1) while significantly outperforming the non-semantic/rule-based baselines.
@article{wickramarachchi2021knowledge, title = {Knowledge-infused Learning for Entity Prediction in Driving Scenes}, author = {Wickramarachchi, Ruwan and Henson, Cory and Sheth, Amit}, journal = {Frontiers in Big Data}, volume = {4}, number = {759110}, pages = {98}, year = {2021}, publisher = {Frontiers}, } - ISWC2021
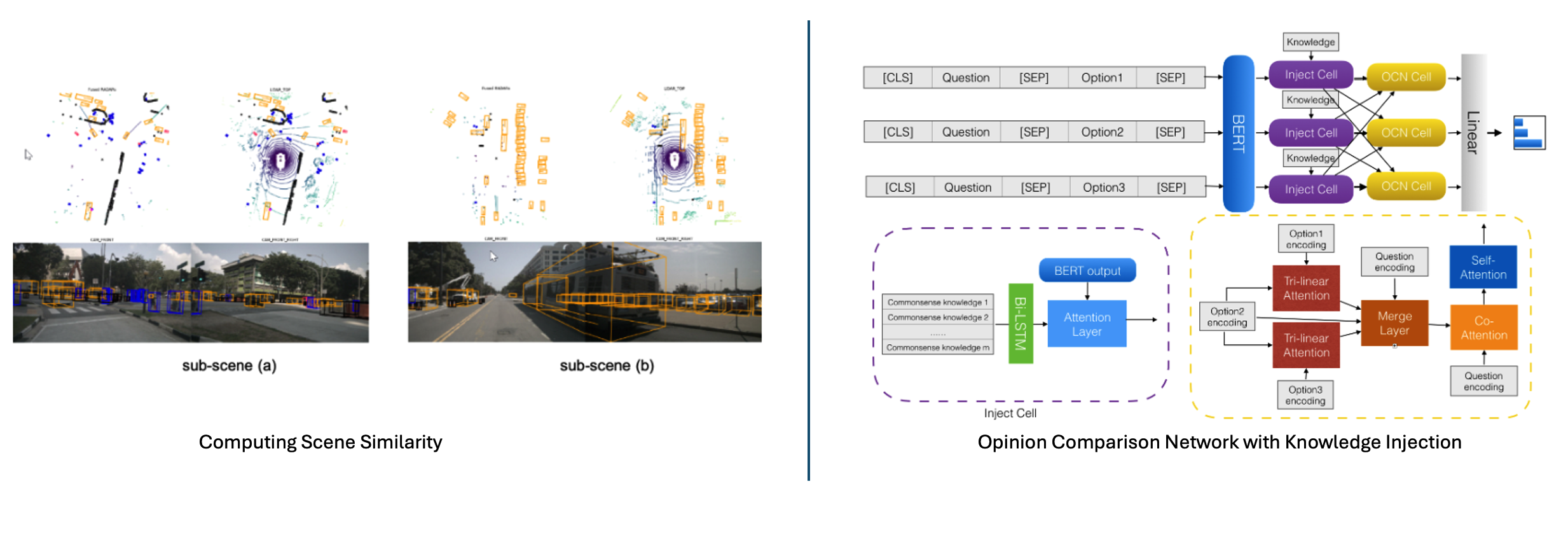
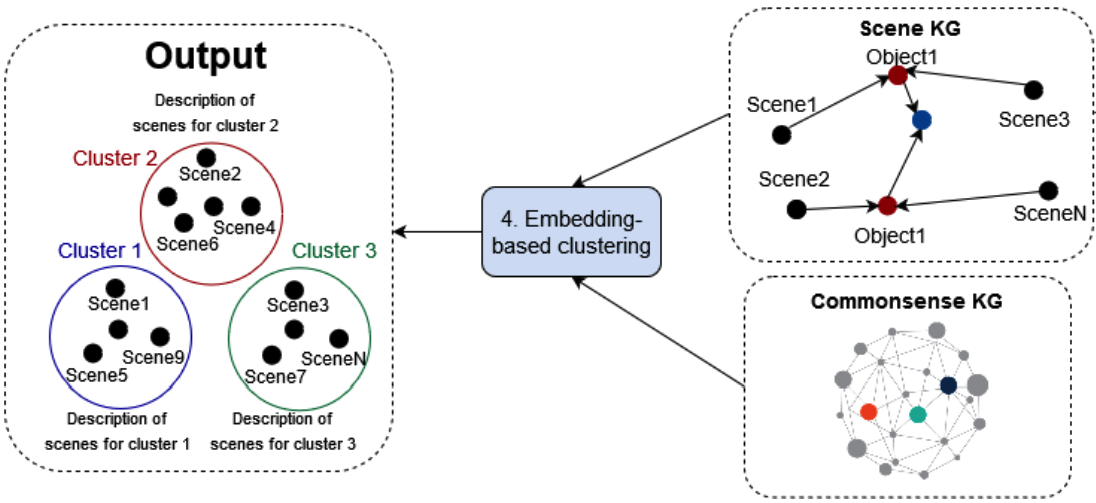 Towards leveraging commonsense knowledge for autonomous drivingSreyasi Nag Chowdhury, Ruwan Wickramarachchi, Mohamed Hassan Gad-Elrab, and 2 more authorsIn 20th International Semantic Web Conference, Oct 2021
Towards leveraging commonsense knowledge for autonomous drivingSreyasi Nag Chowdhury, Ruwan Wickramarachchi, Mohamed Hassan Gad-Elrab, and 2 more authorsIn 20th International Semantic Web Conference, Oct 2021Rapid development of autonomous vehicles has enabled the collection of huge amounts of multimodal road traffic data resulting in large knowledge graphs for autonomous driving. These knowledge graphs typically storing factual statements like “scene 1 includes parking area”, have proved to be useful complements for computer vision models especially for tasks like object prediction in a scene. However, they do not capture inter-object commonsense relationships (e.g., “car is smaller than truck ” or “car accelerates faster than bicycle”), on which human drivers rely subconsciously when making decisions. Existing commonsense repositories target mainly general purpose domains, and their coverage with respect to driving scenarios is very limited, prohibiting a straightforward integration. To bridge this gap, we extend existing autonomous driving knowledge graphs with commonsense knowledge, and demonstrate empirically the benefits of such extension for two downstream applications: object prediction and explainable scene clustering.
@inproceedings{nag2021towards, title = {Towards leveraging commonsense knowledge for autonomous driving}, author = {Nag Chowdhury, Sreyasi and Wickramarachchi, Ruwan and Gad-Elrab, Mohamed Hassan and Stepanova, Daria and Henson, Cory}, booktitle = {20th International Semantic Web Conference}, pages = {1--5}, year = {2021}, organization = {CEUR-WS}, }
2020
- AAAI-MAKE
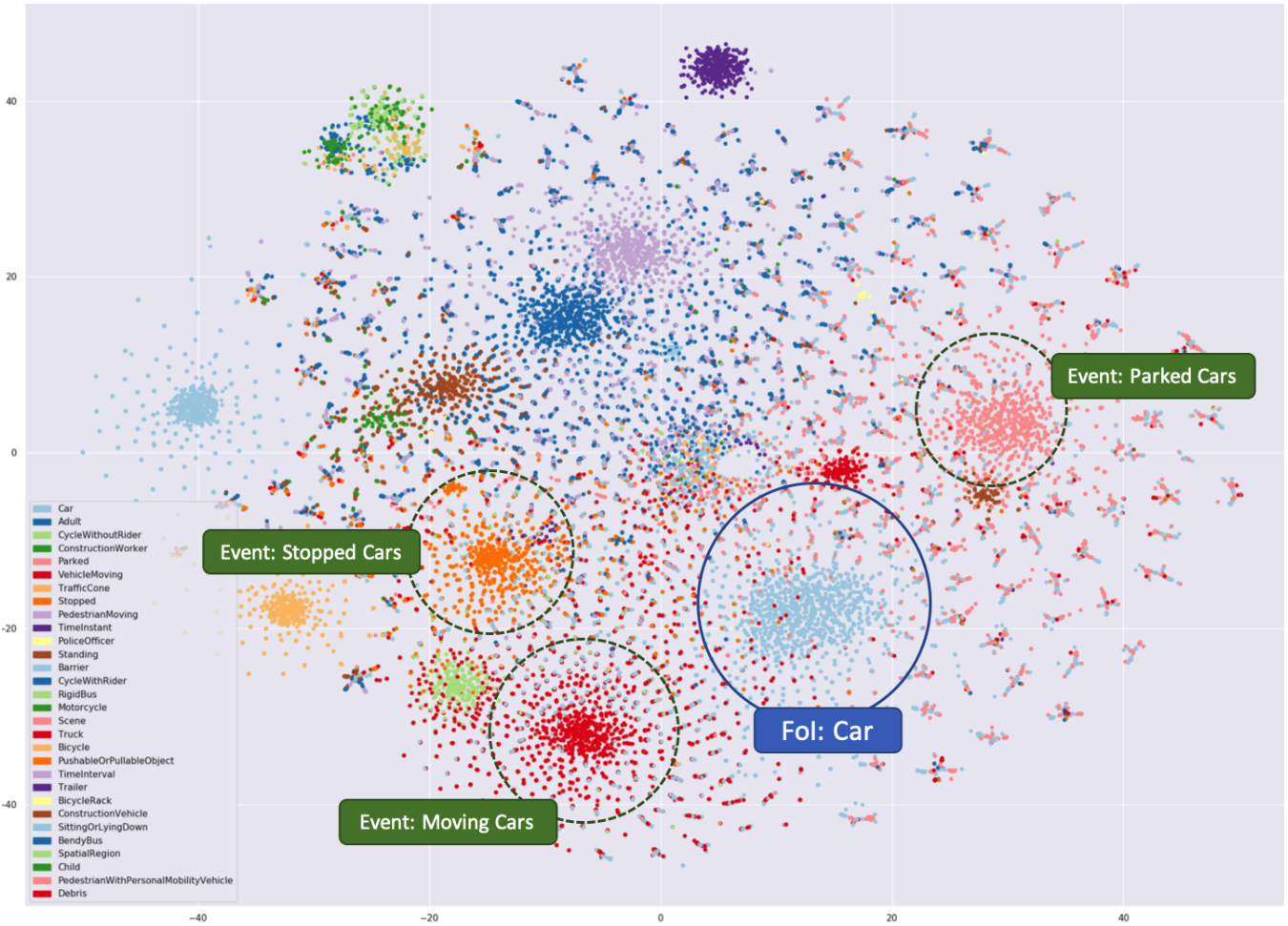 An Evaluation of Knowledge Graph Embeddings for Autonomous Driving Data: Experience and PracticeRuwan Wickramarachchi, Cory Henson, and Amit ShethIn Proceedings of the AAAI 2020 Spring Symposium on Combining Machine Learning and Knowledge Engineering in Practice (AAAI-MAKE 2020), Oct 2020
An Evaluation of Knowledge Graph Embeddings for Autonomous Driving Data: Experience and PracticeRuwan Wickramarachchi, Cory Henson, and Amit ShethIn Proceedings of the AAAI 2020 Spring Symposium on Combining Machine Learning and Knowledge Engineering in Practice (AAAI-MAKE 2020), Oct 2020The autonomous driving (AD) industry is exploring the use of knowledge graphs (KGs) to manage the vast amount of heterogeneous data generated from vehicular sensors. The various types of equipped sensors include video, LIDAR and RADAR. Scene understanding is an important topic in AD which requires consideration of various aspects of a scene, such as detected objects, events, time and location. Recent work on knowledge graph embeddings (KGEs) - an approach that facilitates neuro-symbolic fusion - has shown to improve the predictive performance of machine learning models. With the expectation that neuro-symbolic fusion through KGEs will improve scene understanding, this research explores the generation and evaluation of KGEs for autonomous driving data. We also present an investigation of the relationship between the level of informational detail in a KG and the quality of its derivative embeddings. By systematically evaluating KGEs along four dimensions – i.e. quality metrics, KG informational detail, algorithms, and datasets – we show that (1) higher levels of informational detail in KGs lead to higher quality embeddings, (2) type and relation semantics are better captured by the semantic transitional distance-based TransE algorithm, and (3) some metrics, such as coherence measure, may not be suitable for intrinsically evaluating KGEs in this domain. Additionally, we also present an (early) investigation of the usefulness of KGEs for two use-cases in the AD domain.
@inproceedings{wickramarachchi2020evaluation, title = {An Evaluation of Knowledge Graph Embeddings for Autonomous Driving Data: Experience and Practice}, author = {Wickramarachchi, Ruwan and Henson, Cory and Sheth, Amit}, booktitle = {Proceedings of the AAAI 2020 Spring Symposium on Combining Machine Learning and Knowledge Engineering in Practice (AAAI-MAKE 2020)}, year = {2020}, } - IOS-Press
 Neuro-symbolic architectures for context understandingAlessandro Oltramari, Jonathan Francis, Cory Henson, and 2 more authorsIn Knowledge Graphs for eXplainable Artificial Intelligence: Foundations, Applications and Challenges, Oct 2020
Neuro-symbolic architectures for context understandingAlessandro Oltramari, Jonathan Francis, Cory Henson, and 2 more authorsIn Knowledge Graphs for eXplainable Artificial Intelligence: Foundations, Applications and Challenges, Oct 2020Computational context understanding refers to an agent’s ability to fuse disparate sources of information for decision-making and is, therefore, generally regarded as a prerequisite for sophisticated machine reasoning capabilities, such as in artificial intelligence (AI). Data-driven and knowledge-driven methods are two classical techniques in the pursuit of such machine sense-making capability. However, while data-driven methods seek to model the statistical regularities of events by making observations in the real-world, they remain difficult to interpret and they lack mechanisms for naturally incorporating external knowledge. Conversely, knowledge-driven methods, combine structured knowledge bases, perform symbolic reasoning based on axiomatic principles, and are more interpretable in their inferential processing; however, they often lack the ability to estimate the statistical salience of an inference. To combat these issues, we propose the use of hybrid AI methodology as a general framework for combining the strengths of both approaches. Specifically, we inherit the concept of neuro-symbolism as a way of using knowledge-bases to guide the learning progress of deep neural networks. We further ground our discussion in two applications of neuro-symbolism and, in both cases, show that our systems maintain interpretability while achieving comparable performance, relative to the state-of-the-art.
@incollection{oltramari2020neuro, title = {Neuro-symbolic architectures for context understanding}, author = {Oltramari, Alessandro and Francis, Jonathan and Henson, Cory and Ma, Kaixin and Wickramarachchi, Ruwan}, booktitle = {Knowledge Graphs for eXplainable Artificial Intelligence: Foundations, Applications and Challenges}, pages = {143--160}, year = {2020}, publisher = {IOS Press}, }
2019
- IEEE-IC
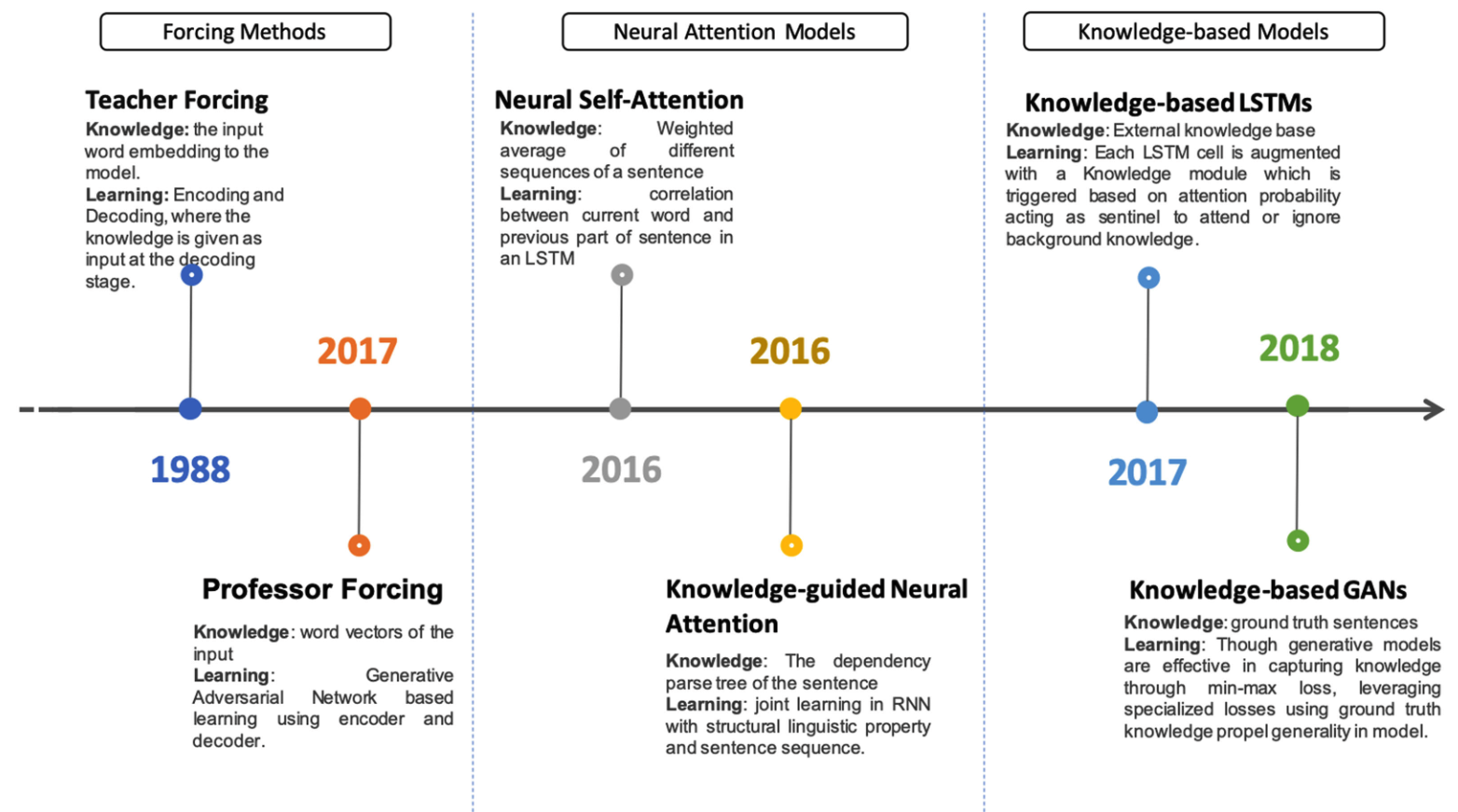 Shades of knowledge-infused learning for enhancing deep learningAmit Sheth, Manas Gaur, Ugur Kursuncu, and 1 more authorIEEE Internet Computing, Oct 2019
Shades of knowledge-infused learning for enhancing deep learningAmit Sheth, Manas Gaur, Ugur Kursuncu, and 1 more authorIEEE Internet Computing, Oct 2019Deep Learning has already proven to be the primary technique to address a number of problems. It holds further promise in solving more challenging problems if we can overcome obstacles, such as the lack of quality training data and poor interpretability. The exploitation of domain knowledge and application semantics can enhance existing deep learning methods by infusing relevant conceptual information into a statistical, data-driven computational approach. This will require resolving the impedance mismatch due to different representational forms and abstractions between symbolic and statistical AI techniques. In this article, we describe a continuum that comprises of three stages for infusion of knowledge into the machine/deep learning architectures. As this continuum progresses across these three stages, it starts with shallow infusion in the form of embeddings, and attention and knowledge-based constraints improve with a semideep infusion. Toward the end reflecting deeper incorporation of knowledge, we articulate the value of incorporating knowledge at different levels of abstractions in the latent layers of neural networks. While shallow infusion is well studied and semideep infusion is in progress, we consider Deep Infusion of Knowledge as a new paradigm that will significantly advance the capabilities and promises of deep learning.
@article{sheth2019shades, title = {Shades of knowledge-infused learning for enhancing deep learning}, author = {Sheth, Amit and Gaur, Manas and Kursuncu, Ugur and Wickramarachchi, Ruwan}, journal = {IEEE Internet Computing}, volume = {23}, number = {6}, pages = {54--63}, year = {2019}, publisher = {IEEE}, }
2013
- ICCSE
 A Lightweight Approach to Simulate a 2D Radar Coverage for Virtual Maritime EnvironmentsWarunika Ranaweera, Shazan Jabbar, Ruwan Wickramarachchi, and 5 more authorsOct 2013
A Lightweight Approach to Simulate a 2D Radar Coverage for Virtual Maritime EnvironmentsWarunika Ranaweera, Shazan Jabbar, Ruwan Wickramarachchi, and 5 more authorsOct 2013Virtual simulation systems present a cost effective way of training the mariners to navigate a ship in a realistic maritime environment. To offer a better training session, a need arises to model other tools and components as a part of the virtual simulation system, such as radar, sonar and telescope, that are used to navigate a vessel in the real world. Taking a light-weighted approach, we developed a virtual radar coverage for the Vidusayura virtual maritime learning environment. It simulates an actual marine radar, which gathers information of its surroundings from the virtual environment with which a trainee naval officer interacts. The impact and the effectiveness of the virtual radar system, in terms of the trainee, is also analyzed against a real radar simulation system.
@article{ranaweera2013lightweight, title = {A Lightweight Approach to Simulate a 2D Radar Coverage for Virtual Maritime Environments}, author = {Ranaweera, Warunika and Jabbar, Shazan and Wickramarachchi, Ruwan and Weerasinghe, Maheshya and Gunathilake, Naduni and Keppitiyagama, Chamath and Sandaruwan, Damitha and Samarasinghe, Prabath}, jornal = {International Conference on Computer Science & Education (ICCSE)}, year = {2013}, }
2012
- ICTer2012
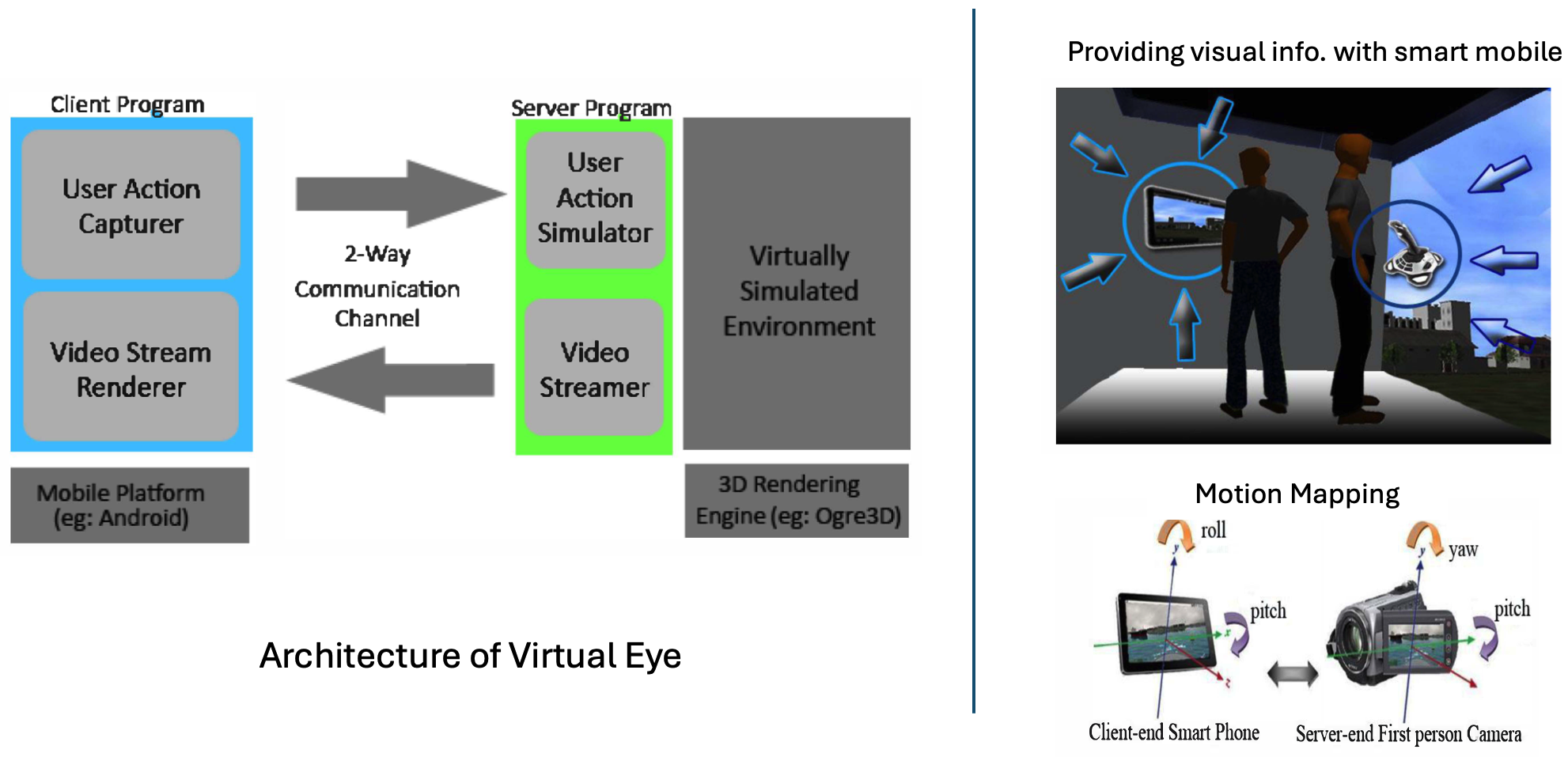 Virtual eye: A sensor based mobile viewer to aid collaborative decision making in virtual environmentsWarunika Ranaweera, Ruwan Wickramarachchi, Shazan Jabbar, and 5 more authorsIn International Conference on Advances in ICT for Emerging Regions (ICTer2012), Oct 2012
Virtual eye: A sensor based mobile viewer to aid collaborative decision making in virtual environmentsWarunika Ranaweera, Ruwan Wickramarachchi, Shazan Jabbar, and 5 more authorsIn International Conference on Advances in ICT for Emerging Regions (ICTer2012), Oct 2012Current virtual simulation techniques often include multi-user interactivity in virtual environments that can be controlled in real time. Such simulation techniques are mostly employed in virtual military training sessions and in real time gaming experiences, where users have to make more strategic decisions by analyzing the information they receive, in response to the actions of the other users in the same virtual environment. Generally, in the real world, collaborative decision making takes place when a team of people work together to control the behaviour of a single object which cannot be handled alone by an individual. A ship with its crew can be held as an example. When applying this scenario into virtually simulated environments, multiple users have to involve in representing a single object in the virtual world. These users need to obtain sufficient information about the activities in the environment that will contribute to the collaborative decision making process. Out of many sources, visual information is the most reliable source the users tend to depend on. The use of traditional static displays to obtain visual information limits the capability of providing a rich set of information about the 3D environment. Head Mounted Displays address these limitations while introducing several new problems. On the otherhand, our work is focused on exploring how smart devices can be employed by a collaboratively working team of users to obtain visual information to the level beyond which a static display provides, thus aiding the process of decision making. To serve the above purpose, we propose a solution, “Virtual Eye”, which uses a smart mobile device with the ability to view the visual output of the virtual world and the ability to control that view according to user’s orientation changes and movements with the use of its inbuilt sensors.
@inproceedings{ranaweera2012virtual, title = {Virtual eye: A sensor based mobile viewer to aid collaborative decision making in virtual environments}, author = {Ranaweera, Warunika and Wickramarachchi, Ruwan and Jabbar, Shazan and Weerasinghe, Maheshya and Gunathilake, Naduni and Keppitiyagama, Chamath and Sandaruwan, Damitha and Samarasinghe, Prabath}, booktitle = {International Conference on Advances in ICT for Emerging Regions (ICTer2012)}, pages = {56--61}, year = {2012}, organization = {IEEE}, }